近日,一款名为FormulaOne的全新AI测评基准引起了广泛关注。该基准测试由专注于超级智能和先进人工智能系统的研究机构AAI推出,挑战了GPT-5、Grok4、o3Pro等多款顶级人工智能模型。结果令人惊讶:所有这些模型在测试中都得分为零!
FormulaOne基准测试包含220个精心设计的图结构动态规划问题,这些问题难度横跨中等至科研级别,涉及拓扑、几何和组合等多个复杂领域。尽管问题表述简洁明了,但背后所需的推理和逻辑推演难度极高,堪称AI领域的“博士级”挑战。
这一系列问题依赖于 Courcelle 提出的一个算法元定理,该定理强调对于每个树状图,任何逻辑中可定义的问题都可以使用动态规划算法来求解。这需要使用一种称为树分解的结构,它将图的顶点组织成一系列排列成树状结构的重叠集合,然后使用动态规划逐步求解它们。
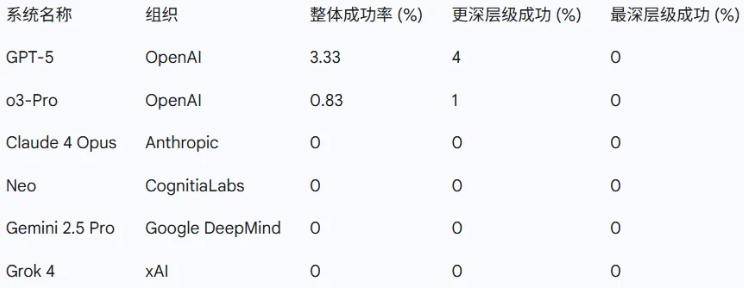
在测试初期,这些前沿AI模型在较为简单的问题上尚能维持一定成功率,范围在50%至70%之间,显示出它们对这类问题有一定的理解和应对能力。然而,随着问题难度的加深,这些模型的表现开始急剧下滑。在深层难度测试中,Grok4、Gemini-Pro等模型几乎全军覆没,仅能解决极少数问题,而GPT-5Pro虽稍胜一筹,也仅成功解答了四道题。至于最深层的难度测试,所有模型均未能斩获任何分数,遭遇了彻底的失败。
这一评估结果引发了学术界的广泛讨论,也引发了对AI模型真实能力的质疑。许多人甚至建议人类博士生也应该参加评估。随着AI技术的飞速发展,我们必须扪心自问:这些模型距离真正实现“博士级”的推理能力还有多远?

发表回复