阿里通义正式推出新一代端到端语音识别大模型Fun-ASR。该模型通过增强上下文感知和高精度转写能力,在家装、保险等垂直行业场景中实现了语音识别准确率突破15%以上。测试数据显示,保险行业准确率较上一代提升18%,家装、畜牧板块则提升15%-20%。
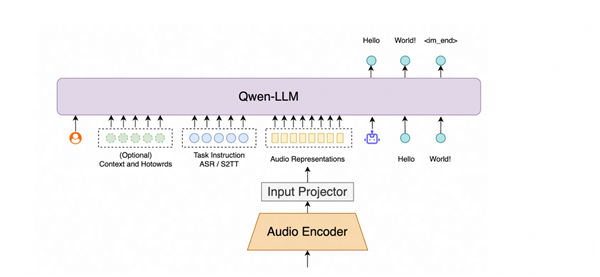
据了解,Fun-ASR是大语言模型驱动的语音识别算法,其基于自研语音算法和监督微调的Qwen3训练,并采用前沿的模型架构以及先进的文本模态对齐技术,可有效保护和增强大模型的语言处理能力;
此外,Fun-ASR集成了RAG方案,可提供自动化音频信息检索功能,最高可导入1000多个自定义热词。
基于该功能,系统能够根据输入音频精确获取相关领域热词、文档及前文记录,大幅提升特定领域内的关键词识别效果。
针对语音识别中的噪声干扰、语言混乱、生成幻觉等痛点,开发团队创新性地引入了强化学习(RL)技术,通过动态优化策略减少识别误差,从而大幅提高了系统的稳定性和可靠性。值得注意的是,该模型在识别川话、粤话、闽南语等方言方面优于同类产品,并适应远场拾音、近场降噪等复杂声学环境,覆盖会议室、工作站、超市、户外区域等多种场景。
在训练数据方面,Fun-ASR 建立在数亿小时的音频数据之上,深度整合了互联网、科技、畜牧、汽车等十多个领域的专业术语库。这种数据优势使其在垂直行业识别方面展现出显著优势,例如,在畜牧业的动物声音和环境噪声中准确识别关键命令。

发表回复